SQL
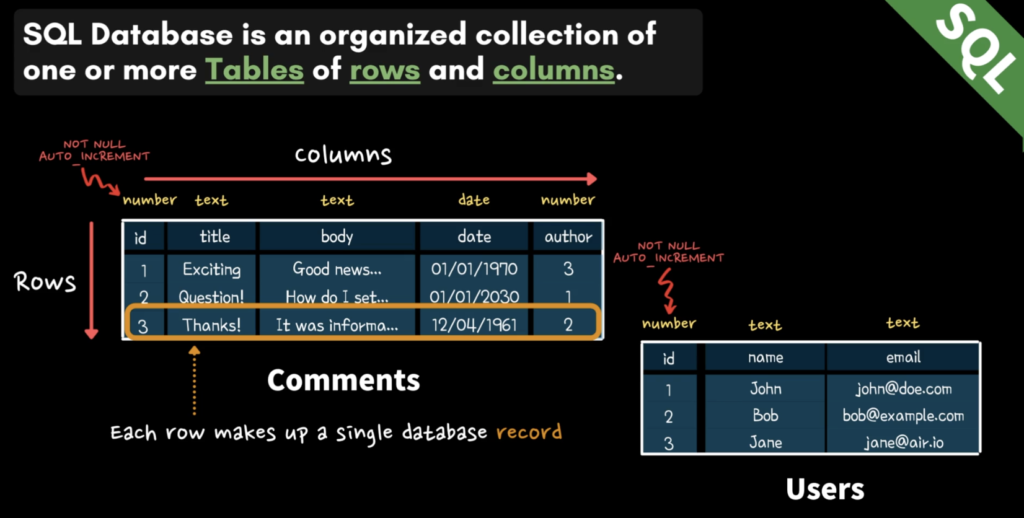
SQL 데이터베이스는 Table, Row, Column 으로 구성되어 있다. 엑셀과 흡사하나, 각 행마다 특정한 데이터 타입을 지정한다는 것에 차이가 있다. 이런 데이터 타입 뿐만 아니라 여러 속성을 지정할 수 있는데 NOT NULL, AUTO_INCREMENT 등의 속성을 부여할 수 있다.
이처럼 데이터베이스에서는 Table, Column, Row 와 각각의 데이터 타입을 지정해주는데, 이렇게 정의된 것을 Schema(스키마) 라 한다. 이렇게 데이터베이스는 스키마를 통해, 데이터의 무결성을 보장할 수 있다. 스키마에서 정의한데로만 데이터를 넣을 수 있기 때문이다.
데이터베이스의 Keys
- Primary key
- 테이블에서 고유한 식별자
- primary key로 데이터베이스가 검색에 최적화를 해주기 때문에, primary 키로 데이터를 찾는다면 조금 더 빠르게 찾을 수 있음
- Foreign key
- 두가지의 다른 테이블의 관계를 정할때 사용하는 키
NoSQL
NoSQL은 1990년대 중반 즈음에 오브젝트를 기반으로한 프로그래밍에서 어떻게하면 DB에 저장할 수 있는지에 대해 많은 고민이 있었다. 그래서 오브젝트를 그냥 저장할 수 있는 오브젝트형 데이터베이스가 나오게 되는데, 이것은 그렇게 큰 호응을 받진 못했다.
2000년대 중반, 인터넷이 급성장하면서 많은 사람들이 인터넷으로 데이터를 주고받고, 빅데이터가 뜨기 시작하면서 NoSQL이 뜨기 시작했다.
구글에서 BigTable이 나오고, 아마존에서 DynamoDB가 나오면서 많은 사람들이 Nosql에 대해 알게되고, 빅데이터에 적합하다라고 생각되면서 뜨기 시작했다.
NoSQL의 특징은 ?!
- 스키마가 없다.
- 관계형이 아니다.
- 자체적으로 고립된 형태로 관리가 가능하다
- 관리하고자하는 데이터를 분산해서 다른 서버에서 관리하기가 용이
- 용도에 따라 특수한 문제를 해결할 수 있다.
- Key-Value
- Document
- Wide-column
- Graph

웹상에서 많이 사용되어지는 mongoDB는 Document 데이터베이스 방식이다. 하나의 데이터는 document로 관리되고, 관련있는 데이터를 묶어주는 collection 이 있다.
예를 들어 Product 라는 Collection 이 있다면, Product 라는 하나의 폴더가 있는 것과 비슷하다. 이 제품이라는 폴더안에 각 제품마다 별도의 document로 관리된다. 그렇기 때문에 Product collection, User collection 와 같이 각각의 collection은 서로 관계가 없으므로 제품에 관련된 collection은 다른 서버에 저장해두고, 유저에 관련된 collection은 클라우드에 배포하는 등 각각 개별적으로 관리하기가 용이하다.
그래서 보통 NoSQL 을 사용할때는 서로 관계가 없으므로, 만약 제품에서 사용자에 대한 정보가 필요하다면 차라리 사용자의 정보를 제품에 포함해서 데이터를 중복해서 관리하는 것을 더 선호한다. NoSQL 에서 관계를 가지기 시작하면, NoSQL에서 가질 수 있는 여러가지 장점들이 없어지는 것이기 때문이다.
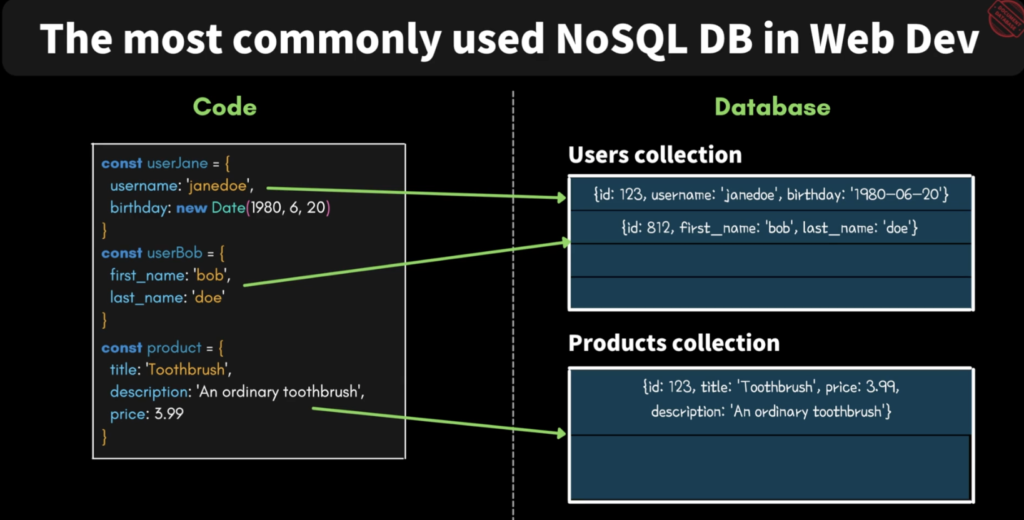
위 코드에서 Jane과 Bob은 User collection 에 하나의 오브젝트로서 저장된다. Product도 마찬가지로, product collection 안에 하나의 오브젝트로서 들어가게된다.
중요한 포인트는 NoSQL에는 스키마가 없으므로 Users collection 안에 어떤 데이터를 저장하던, Jane이라는 document 안에 어떤 데이터를 저장하든 상관없다. 데이터베이스 입장에서는 스키마가 없기때문에 어떤 데이터가 정확한지 알 수 없으므로 User collection에 product 데이터를 저장해도 오류가 나지 않는다. 그래서 개발자가 스스로 collection을 잘 관리해야한다.
핫한 NoSQL 데이터베이스


