최근 회사에서 si성으로 쇼핑몰 플랫폼의 api 서버를 구축해주는 프로젝트를 진행했다. 내가 다시 메시지큐 서비스를 구축하게 될 줄이야.. 이전에 메신저 통합 솔루션을 개발할때 사용했던 RabbitMQ 서비스가 마지막인 줄 알았더니..
그래도 이전에 메시지큐 서비스를 한번 경험해본터라 접근은 크게 어렵지않았다.
우리는 외주사이면서 소스 DB에는 다이렉트로 접근을 할 수가 없다보니, 소스 DB에서 replication 처리를 해서 거기로부터 읽어올까 생각했지만 이러면 api 서버가 필요한 테이블만 가져오는게 아닌 전체 db를 가져와야하기때문에 리소스 낭비라고 판단했다. 그리고 추후 통계형 DB로도 활용이 가능하니,, 겸사겸사 사용해보았다.
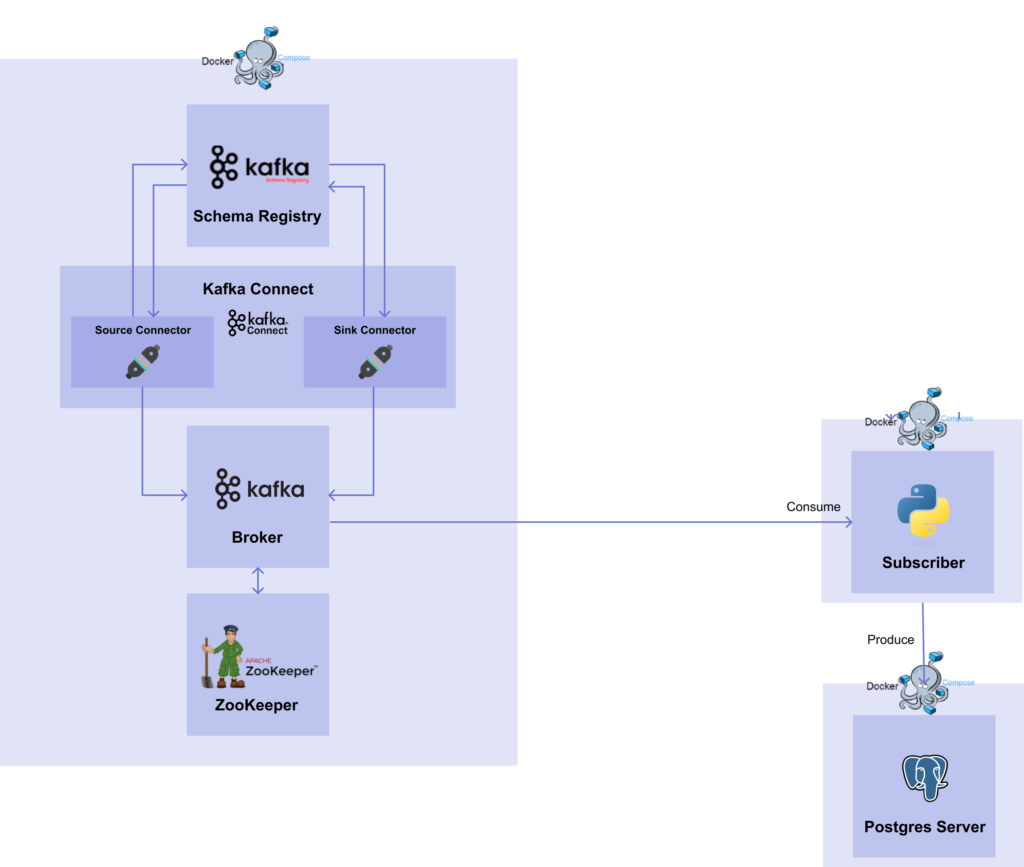
나는 편의성 / 실서버 배포를 위해 kafka 서비스에 필요한 대부분을 도커라이징해서 사용했다. sink db에 데이터를 정상적으로 적재하기 위해 kafka 서비스를 위한 컨테이너, 데이터를 consume 하여 가공 / sink db에 적재하는 역할을 하는 data subscriber 서비스를 위한 컨테이너가 필요했다.
우선 kafka에 대해 알아보자.
kafka 특징
1. 높은 처리량 (High throughput)
- batch기능을 제공하여 짧은 시간안에 대량의 데이터를 consumer까지 전달가능
- 대용량 실시간 로그처리에 특화
2. 확장성 (Scalability), 고가용성(High Availability)
- 쉽게 Broker, Partition, Consumer Group 추가 가능
- Broker 확장
- 복제본(replication)을 늘려서 데이터 유실 방지
- 너무 늘렸을 시, 성능 저하의 이슈 + 높은 리소스 사용량
- Partition 확장
- 데이터 처리 분산
- 늘렸다가 다시 줄이는 것이 어려움 (Topic전체 삭제해야함)
- 리소스낭비 + 장애 복구 시간 증가
- Consumer Group 확장
- 병렬처리
- Broker 확장
- Topic 내 Partition 복제 가능
- 복제 수만큼 Partition의 복제본이 각 Broker에 생김
3. 낮은 의존도
- 소스와 타겟 어플리케이션의 의존도를 낮춰줌
- 여러 Producer, Consumer가 상호 간섭 없이 메세지 쓰고 읽기 가능
- Broker는 Consumer와 Partition간 매핑 관리만 집중
- 메세지 필터, 재전송과 같은 일들은 Producer와 Consumer에 위임
4. 이벤트 보존성
- 한번 이벤트가 Partition에 저장되면 정해진 retension 기간동안 보존
- Consumer가 항상 떠있지 않아도,
offset을 통한 읽던 위치 기억 - Partition의 이벤트들은 파일시스템에 저장됨
5. Page Cache & Zero Copy
–Page Cache : 처리한 데이터를 RAM에 올려서 데이터에 대한 접근이 발생할 때 Disk IO를 발생시키지 않고 처리할 수 있는 기법 (운영체제 자체에서 최적화한 page cache 메모리를 이용)
–Zero Copy : 일반적으로는 Disk에서 데이터를 읽고 RAM에 올리고 네트워크 전송을 하지만, Zero Copy는 Disk에서 데이터를 읽음과 동시에 네트워크 전송을 함
- Producer가 Broker에 데이터를 적재할 때 즉시 Disk에 파일을 저장하는 대신
Page Cache에 저장 -> 일정 시간 후 Disk에 파일 쓰기 - Consumer가 데이터를 Broker에서 읽어갈 때 데이터를
Page Cache에 올려두어 동일 데이터를 다른 Consumer가 읽을 때 빠르게 읽을 수 있게 함 - 일반적으로는 Disk IO시간이 많이 소요되기때문에 Disk기반이라 하면 느리게 보일 수 있지만 위와 같은 처리를 통해 빠른 속도를 유지
kafka 용어 정의
Topic
Kafka는 이벤트 기반 스트리밍 플랫폼이다. Kafka에 전달되는 메세지 스트림의 추상화된 개념을 Topic이라부름.
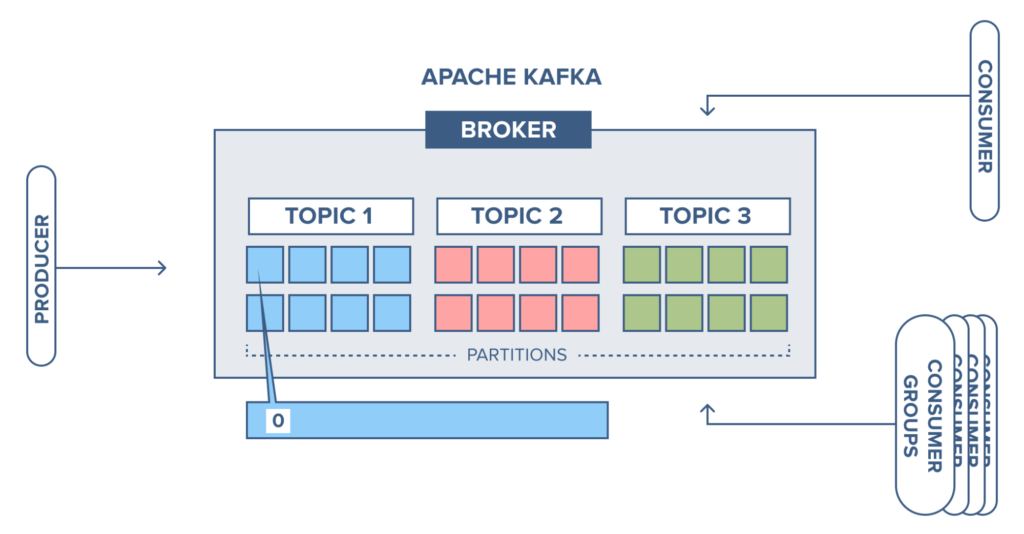
이벤트를 만들어내는 Producer가 어떤 Topic에 데이터를 적재할건지, Consumer는 어떤 Topic에서 데이터를 읽을건지(구독할건지) 결정
Topic은 여러개 생성할 수 있으며, 각각의 메세지를 목적에 맞게 구분할때 사용. 테이블별로 Topic을 자동생성해주는 기능도 제공 (구분을 위한 prefix 지정)
Partition
각 Topic은 내부에 더 세분화된 단위인 Partition을 가지고 있다.
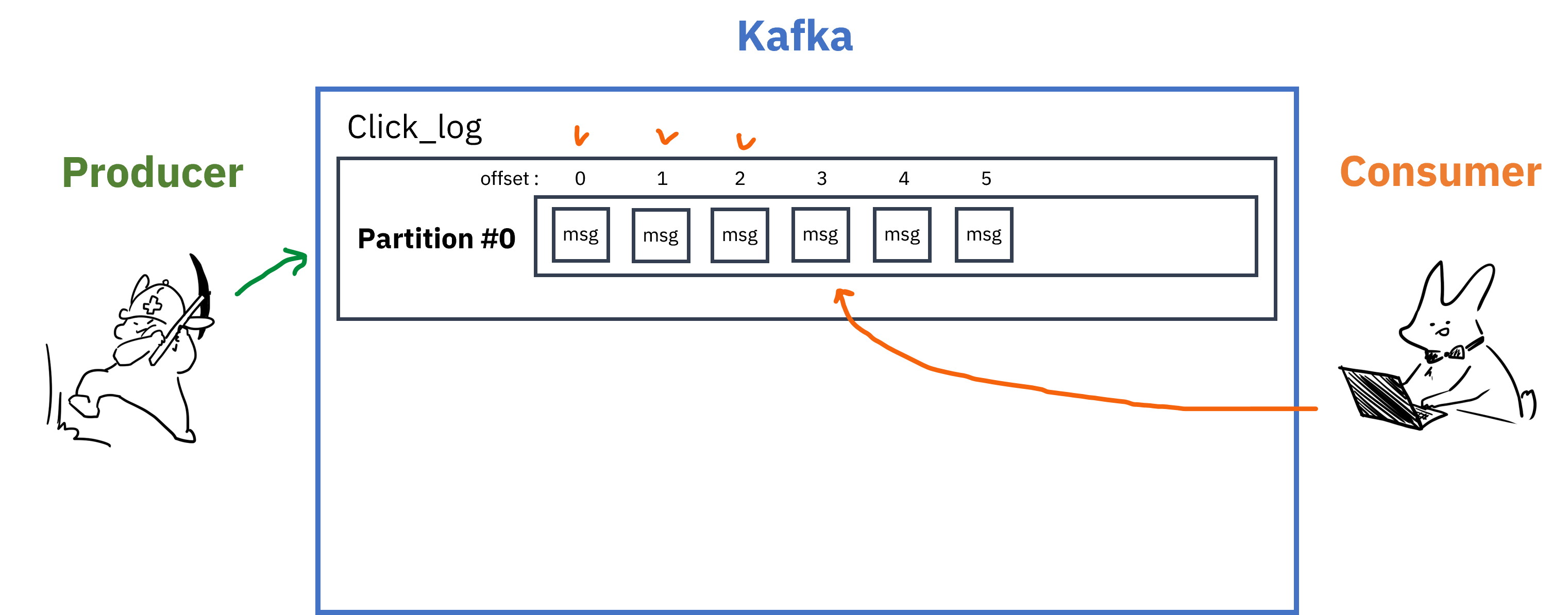
- 메세지가 들어오면 순차적으로 추가되며, Consumer가 메세지를 읽을 때에는 Queue의 선입선출(FIFO)과 비슷하게 오래된 메세지부터 읽게됨
- Queue와 다른 점은 레코드를 읽어도 사라지지 않는다는 점
- 이게 가능한 이유는 Queue가 아닌 실제 파일시스템에 데이터가 저장되기 때문
- 때문에 Consumer처리가 늦거나 Kafka클러스터에 문제가 생겨도 메세지 손실이 발생하지 않음
- Consumer가 Partition의 레코드를 읽을 때에는
offset이라는 저장위치를 기억하고 있어서 문제가 생겨도 읽던 위치부터 다시 읽기 가능 - Partition에는 여러 Consumer 그룹이 붙을 수 있고, 그룹이 다르고 auto.offset.reset=earlist 일 경우 각 Consumer 그룹은 0번 레코드부터 읽기 시작함
Topic은 하나 이상의 Partition을 가질 수 있는데, 여러개의 Partition을 가지고 있는 경우는 아래와 같음.
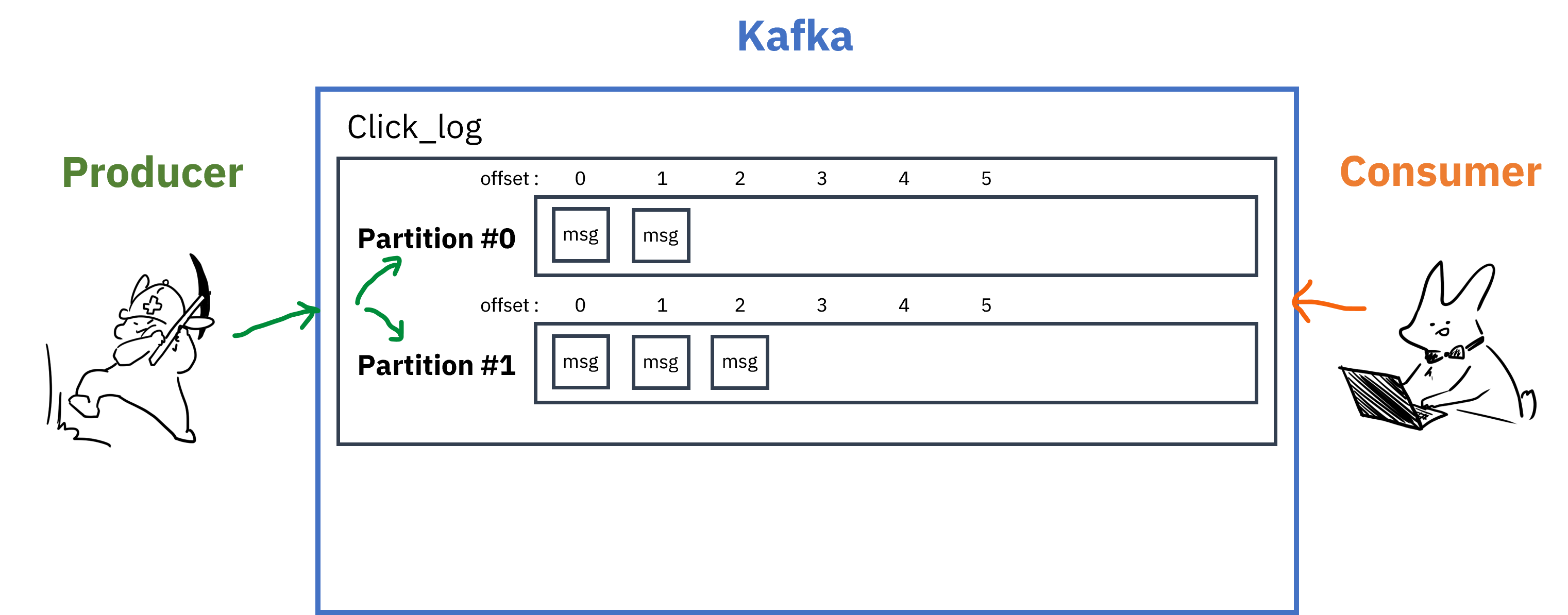
- 데이터를 적재할 시, 키값을 지정해주어 특정 Partition에만 데이터 적재 가능
- 키값을 지정해주지 않았을 경우, Round-robin방식으로 데이터 적재
- Partition을 늘리는 것은 가능하지만 줄일수는 없음 (없애려면 Topic 전체를 삭제)
- Partition을 늘리면 Consumer를 늘려서 데이터 처리를 분산할 수 있음
- Partitioning을 통한 분산 처리로, 데이터의 순서가 보장되면서 성능을 향상시킬 수 있음
예를 들어서 3개의 Producer에서 1개의 Partiton에 전송되는데 1초가 걸리는 메세지를 보냈다고 가정하면,
MQ시스템 하에서는, 반드시 메세지의 순서가 보장되어야하기 때문에 1초가 걸린다고 해도 이를 모두 처리하는데 총 3초의 시간이 소요된다.
결국 순서를 지키며 병렬적으로 메세지를 처리하기 위해서는 하나의 Topic안에 여러개의 Partition을 둠으로써 처리할 수 있다.
즉, 3개의 Producer가 메세지를 3개의 Partition에다 보낸다면 3초가아닌, 1초 소요.
- 다만 Partition을 늘리는 것이 능사는 아님
- 리소스 낭비 : 각 Partition은 Broker의 directory와 매핑, 저장되는 데이터마다
Index,실제데이터가 저장됨 - 장애복구 시간 증가 : replication을 설정했을 경우, Broker에 장애가 발생하면 각 partition에 대한 리더를 선출해야하므로 partition개수가 많으면 그만큼 시간소요
- 리소스 낭비 : 각 Partition은 Broker의 directory와 매핑, 저장되는 데이터마다
Partition에 저장된 데이터는 삭제할 시점 설정 가능
log.retention.ms: 최대 record 보존시간log.retention.byte: 최대 record 보존크기(byte)
Broker
Broker는 Kafka가 설치되어있는 서버의 단위.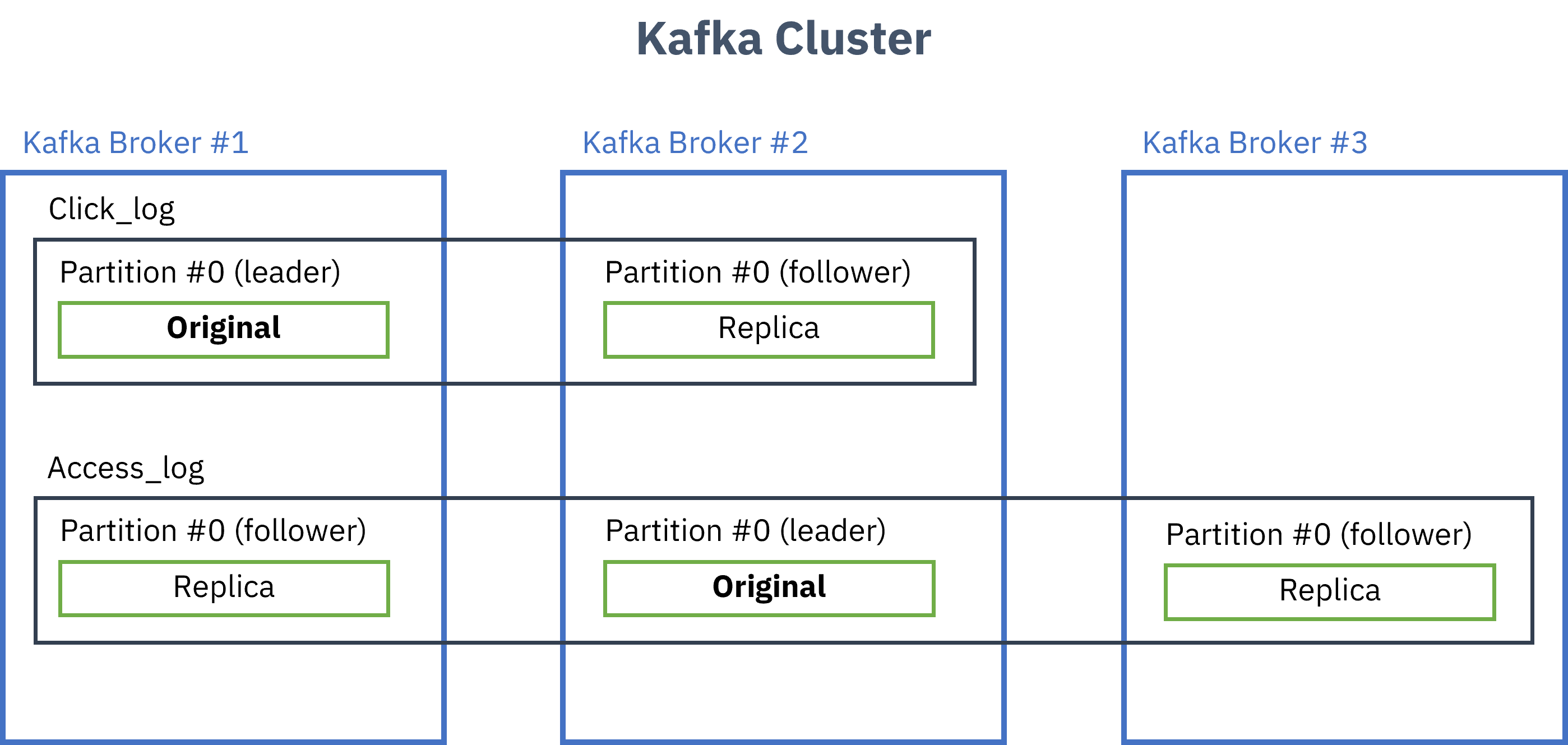
- 보통 3개 이상 권장
- replication을 지정해주면 그 수만큼 원본+복제본 생성
- 원본은 leader partition, 복제본은 follower partition으로 부르며 이를 합쳐서 ISR(In Sync Replica)라고 부름
- leader가 정상적으로 동작하지 않을 경우 follower가 leader의 역할을 대신함
- Producer(kafka-client)는 각 Topic의 leader partition에 데이터를 전송,
ack값을 설정해서 데이터 복제에 대한 commit가능0: leader partition에 데이터 전송하고 응답안받음 (보내는 사이에 데이터유실가능성 있음)1: leader partition에 데이터 전송하고 응답받음 (leader가 받고 follower들한테 복사하기전에 leader가 죽으면 데이터 유실가능성 있음)all: 모든 replica에 데이터 복제 후 응답받음(각 broker들한테서 응답받음, 데이터유실X, 속도느림)
- replication이 많아질수록 고가용성이 높아지지만 저장공간도 많이 필요하고(n배), Broker 리소스도 많이 사용하게 됨(replication상태체크)
Producer
Producer는 데이터를 만들어내고 Kafka Topic에 데이터를 적재시키는 주체. (나의 경우 kafka connector)
- 특정 Topic으로 데이터를 publish
- kafka broker로 데이터를 전송할때 성공여부를 알려주고, 실패하면 재시도 가능
Consumer
Consumer는 Kafka Topic에서 데이터를 읽어오는 주체.
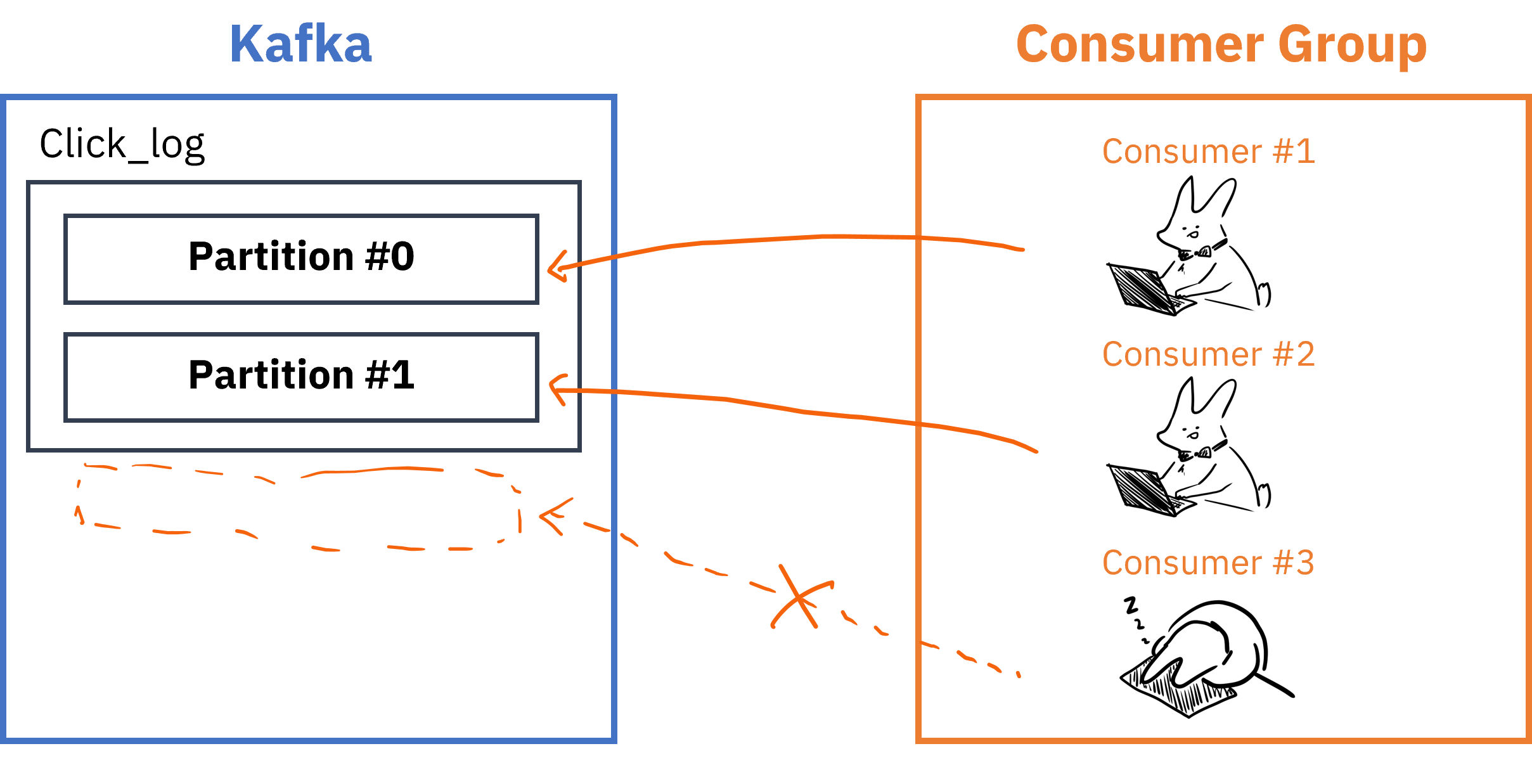
- Consumer가 데이터를 읽은 지표인
offset정보는__consumer_offset토픽에 저장되어 Consumer에 장애가 발생해도 원래 위치부터 읽기 시작 가능 - Topic의 Partition과 Consumer그룹은 1:N매칭으로, 동일 그룹내 한개의 컨슈머만 연결가능 -> 메세지가 순서대로 처리되도록 보장
- Consumer 그룹 내 Consumer 개수는 Partition개수보다 적거나 같아야 함
Consumer Group이 여러개 존재할 경우,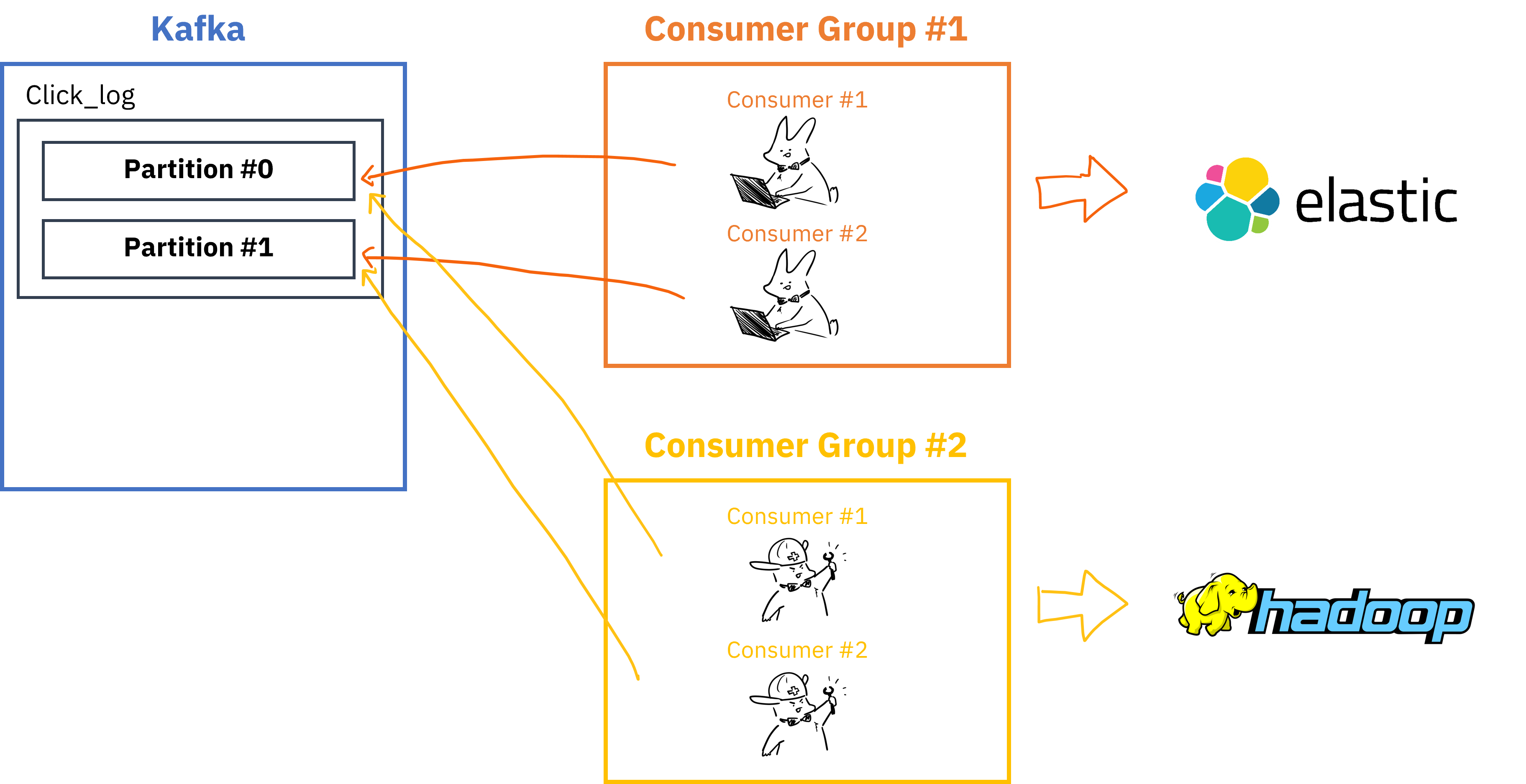
- 여러 Consumer Group을 통해 병렬처리 가능
__consumer_offset토픽에는 Consumer group별/토픽별로 offset을 나눠서 저장하기 때문에 Consumer group이 다르면 각자의 그룹은 서로 영향을 끼치지않음
kafka 서비스 도커라이징
아래는 내가 사용한 kafka 서비스를 위한 compose 파일이다. 모두 동일한 네트워크에 속하게 만들었고, 서비스가 올라간 후에 source connector를 자동으로 추가하도록 volume을 잡았다.
또, 커넥터 연결을 위해서는 jdbc 관련 의존성 설치가 필요하므로 Dockerfile을 이용해서 추가 설치를 해준다.
// kafka-docker-compose
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
container_name: zookeeper
networks:
- service-network
ports:
- 2181:2181
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 2181
broker:
image: confluentinc/cp-kafka:7.3.0
container_name: broker
networks:
- service-network
depends_on:
- zookeeper
ports:
- 9092:9092
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
schema-registry:
image: confluentinc/cp-schema-registry:7.3.0
container_name: schema-registry
networks:
- service-network
depends_on:
- broker
ports:
- 8081:8081
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: broker:29092
SCHEMA_REGISTRY_LISTENERS: http://schema-registry:8081
connect:
build:
context: .
dockerfile: connect.Dockerfile
networks:
- service-network
container_name: connect
depends_on:
- broker
- schema-registry
ports:
- 8083:8083
environment:
CONNECT_BOOTSTRAP_SERVERS: broker:29092
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_GROUP_ID: docker-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONNECT_TOPIC_CREATION_ENABLE: "true"
kafka-manager:
container_name: kafka-manager
networks:
- service-network
image: hlebalbau/kafka-manager:stable
restart: on-failure
depends_on:
- broker
- zookeeper
environment:
ZK_HOSTS: zookeeper:2181
APPLICATION_SECRET: "random-secret"
KM_ARGS: -Djava.net.preferIPv4Stack=true
ports:
- "9000:9000"
kafka-setup:
image: confluentinc/cp-kafka:7.3.1
hostname: kafka-setup
container_name: kafka-setup
networks:
- service-network
depends_on:
- connect
- broker
- schema-registry
volumes:
- ./connectors:/tmp/connectors
command: >
bash -c 'echo Waiting for Kafka to be ready... &&
cub kafka-ready -b broker:29092 1 20 &&
kafka-topics --create --if-not-exists --bootstrap-server broker:29092 --partitions 2 --replication-factor 1 --topic products && // 토픽, 파티션, replication 자동 등록 (broker가 하나라서 replica 는 1개만, 퍼포먼스를 위해 partition 은 우선 2로)
echo Waiting 30 seconds for Connect to be ready... &&
sleep 30 &&
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://connect:8083/connectors/ -d "@/tmp/connectors/source_connector.json"'
environment:
# The following settings are listed here only to satisfy the image's requirements.
# We override the image's `command` anyways, hence this container will not start a broker.
KAFKA_BROKER_ID: ignored
KAFKA_ZOOKEEPER_CONNECT: ignored
networks:
service-network:
external: true
FROM confluentinc/cp-kafka-connect:7.3.0
ENV CONNECT_PLUGIN_PATH="/usr/share/java,/usr/share/confluent-hub-components"
RUN confluent-hub install --no-prompt snowflakeinc/snowflake-kafka-connector:1.5.5 &&\
confluent-hub install --no-prompt confluentinc/kafka-connect-jdbc:10.2.2 &&\
confluent-hub install --no-prompt confluentinc/kafka-connect-json-schema-converter:7.3.0 &&\
confluent-hub install --no-prompt debezium/debezium-connector-mysql:2.2.1
RUN cd /usr/share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib && \
curl -o mysql-connector-java-8.0.25.jar \
https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.25/mysql-connector-java-8.0.25.jar
Source connector 연결 (데비지움)
처음에는 debezium 없이 일반 source connector 로 연결했더니, 각 테이블마다 여러 토픽채널들이 생성되었다. 나의 케이스에서는 데이터의 순서가 중요하기 때문에, 단일 토픽으로 처리가 필요했다. (순서가 맞지 않을 경우 외래키 제약에 걸림)
그래서 서칭하다 알아낸게 debezium에서 제공하는 ByLogicalTableRouter 라우트 기능이다. 여러 테이블의 데이터들을 하나의 토픽으로 전달할 수 있게 해준다.
하기가 내가 연결했던 소스 커넥터 설정이다. 아래 json을 서비스/connectors 로 POST 요청을 보내면 등록이 정상적으로 완료된다.
상태를 점검하고싶거나, 연결된 커넥터를 보거나, 등록된 커넥터를 삭제하는 경로 역시 존재한다.
GET {서비스명}/connectors/ // 연결된 커넥터 조회
GET {서비스명}/connectors/{커넥터명} // 커넥터 상태 체크
DELETE GET {서비스명}/connectors/{커넥터명} // 커넥터 삭제
// source-connector
{
"name":"debezium-source-product-connector",
"config":{
"connector.class":"io.debezium.connector.mysql.MySqlConnector",
"tasks.max":"1",
"database.hostname":"",
"database.port":"3306",
"database.user":"",
"database.password":"",
"database.server.id":"184054",
"database.server.name":"",
"database.include.list":"{db 화이트리스트}",
"topic.prefix": "_",
"transforms": "route",
"transforms.route.type": "io.debezium.transforms.ByLogicalTableRouter",
"transforms.route.topic.regex": ".*",
"transforms.route.topic.replacement": "{토픽 이름}"
}
}
이제 생성된 카프카 토픽 리스트를 확인하고 안에 메시지가 정상적으로 쌓이는지 확인한다. 메시지 확인을 위해서는 도커 컨테이너 내부로 들어가야한다.
// 토픽 채널 확인
$ kafkaa exec -it broker bash
$ kafka-topics --bootstrap-server localhost:9092 --list
// 토픽에 쌓인 데이터 확인
$ docker exec -it broker bash
$ kafka-console-consumer --topic ${topic} --bootstrap-server localhost:9092 --from-beginning
sink connector (data-subscriber)
데이터가 정상적으로 쌓이는걸 확인했다면 이제 데이터를 컨슈밍 해주는 sink connector를 만들어야한다. 일반적인 케이스들에서는 기본으로 제공되는 source connector, sink connector를 사용해서 연결하면 간편하고 쉽지만, 나의 케이스에서는 데이터 순서 보장을 위해 이미 데비지움을 통해 단일 토픽으로 라우팅해서 사용중이므로 데이터를 컨슈밍하여 sink db 내 테이블에 맞게 적재해야한다.
하기는 내가 데이터 컨슈밍을 위해 사용한 도커 컴포즈 파일이다.
# stream-docker-compose.yaml
version: "3"
services:
data-subscriber:
build:
context: .
dockerfile: subscriber.Dockerfile
container_name: data-subscriber
command: python data_subscriber.py
networks:
- linkmom-network
depends_on:
- redis
celery-worker:
build:
context: .
dockerfile: subscriber.Dockerfile
command: celery -A data_subscriber worker --loglevel=info
networks:
- linkmom-network
depends_on:
- redis
redis:
image: redis:latest
container_name: redis
networks:
- linkmom-network
networks:
linkmom-network:
external: true
또한 서비스를 위해 필요한 의존성 & data_subscriber.py 를 설치한다.
FROM amd64/python:3.9-slim
WORKDIR /usr/app
RUN pip install -U pip
RUN apt-get update && apt-get install -y \
pkg-config \
libmariadb-dev-compat \
build-essential \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
#
COPY .env .
COPY data_subscriber.py data_subscriber.py
requirements.txt는 많지는 않고, python 이 kafka 에 접근해서 데이터를 가져오고 db 풀링하는 의존성만 포함하면 된다.
kafka-python python-dotenv requests pymysql pymysql-pool requests cryptography celery[redis]
데이터 컨슈밍 어플리케이션
이제 실제 데이터를 kafka 에서 가져와서 sink db 의 알맞는 테이블로 넣어주는 python 코드를 작성하자. 아래는 샘플이다.
# data_subscriber.py
from json import loads
from kafka import KafkaConsumer
from dotenv import load_dotenv
import os
import pymysqlpool
from datetime import datetime
load_dotenv()
# db config
config = {
'host': os.getenv("DB_HOST"),
'user': os.getenv("DB_USER"),
'password': os.getenv("DB_PASSWORD"),
'database': os.getenv("DB_NAME"),
'autocommit': True
}
# set logger(optional)
pymysqlpool.logger.setLevel('DEBUG')
# create pool
pool = pymysqlpool.ConnectionPool(size=3, maxsize=5, pre_create_num=3, name='pool1', **config)
def execute_query(query, data):
connection = pool.get_connection()
try:
with connection.cursor() as cursor:
cursor.execute(query, data)
connection.commit()
except Exception as e:
print(f"Database error: {e}")
connection.rollback()
finally:
connection.close()
def consume_messages():
consumer = KafkaConsumer(
os.getenv("KAFKA_TOPIC"),
bootstrap_servers=os.getenv("KAFKA_BOOTSTRAP_SERVERS"),
auto_offset_reset=os.getenv("KAFKA_AUTO_OFFSET_RESET"),
value_deserializer=lambda x: loads(x.decode('utf-8')),
)
for message in consumer:
if 'payload' in message.value and 'op' in message.value['payload']:
payload = message.value['payload']
table_name = payload['source']['table']
operation = payload['op']
if operation in ['c', 'u', 'r']: # For create, update, and read(snapshot) operations
data = payload['after']
columns = ', '.join(['`' + column + '`' for column in data.keys()])
placeholders = ', '.join(['%s'] * len(data))
on_duplicate_key_update = ', '.join([f"`{column}`=VALUES(`{column}`)" for column in data.keys()])
sql = f"INSERT INTO {table_name} ({columns}) VALUES ({placeholders}) ON DUPLICATE KEY UPDATE {on_duplicate_key_update}"
if 'createdate' in data:
data['createdate'] = datetime.fromtimestamp(data['createdate'] / 1000000.0)
if 'updatedate' in data:
data['updatedate'] = datetime.fromtimestamp(data['updatedate'] / 1000000.0)
execute_query(sql, list(data.values()))
elif operation == 'd': # For delete operations
data = payload['before']
primary_key = list(data.keys())[0] # Assuming first key is the primary key
sql = f"DELETE FROM {table_name} WHERE `{primary_key}` = %s"
execute_query(sql, (data[primary_key],))
else :
continue
if __name__ == "__main__":
consume_messages()
끝!
이제 api 서버는 sink db만 바라보면서 요청에 응답만 해주면 된다~
추가 웹훅 구현
kafka 에 데이터가 적재되었을때 특정 서버에 웹훅을 보내줘야했다. (오프라인 RFID 주문 / 결제 연동 용). data-subscriber 에 데이터에서 데이터를 consuming 했을때 특정 테이블에서 일어난 CRUD 라면 해당 서버로 웹훅을 보내주는걸 python celery[redis 이용]를 이용해서 구현했다. 또한 웹훅 호출 실패에 대한 로그를 남겼다. 아래는 예시이다.
@app.task(bind=True, max_retries=5, default_retry_delay=1)
def send_webhook(self, order_id, url, payload, webhook_type):
# if check_order_id_exists(order_id, webhook_type):
# celery_logger.info(f"Skipping webhook send for order_id {order_id} with type {webhook_type} as it already exists in the database.")
# return
try:
response = requests.post(url, json=payload)
response.raise_for_status()
celery_logger.info(f"({webhook_type}) Webhook successfully sent to {url}")
except requests.RequestException as exc:
attempt_count = self.request.retries + 1
if self.request.retries == self.max_retries:
error_message = str(exc)
celery_logger.error(f"({webhook_type})Final attempt failed for {url} - {error_message}", exc_info=True)
log_webhook_failure(order_id, url, error_message, webhook_type, attempt_count)
else:
celery_logger.error(f"({webhook_type})Webhook sending failed: {url} - {exc}, attempt {attempt_count}", exc_info=True)
raise self.retry(exc=exc)
....
....
if env == 'production' and table_name == 'apps_order_payment_return' and (operation == 'u' or operation == 'c'):
order_id = data.get('order_id')
if order_id is not None:
full_webhook_url = f"{base_webhook_url}?order_id={order_id}"
payload = {}
send_webhook.delay(order_id, full_webhook_url, payload, str(WebhookType.PAYMENT_RETURN))
참고
소스 DB에서 카프카 커넥터를 통해 데이터를 가져오려면, mysql user 에 최소 아래 권한 & binary log 설정은 있어야한다.
grant replication slave, replication client, select on *.* to ‘user’@’host’;
추가 이슈
- kafka에서 : The server time zone value ‘KST’ is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the ‘connectionTimeZone’ configuration property) to use a more specific time zone value if you want to utilize time zone support. 이러한 에러가 날경우
- 커넥터에 타임존을 명시해주자.
- “database.connectionTimeZone”: “Asia/Seoul”
- connection refused
- 방화벽이나 인터넷 설정등 다양한 원인이 있을 수 있겠지만, 나의 경우에는 kafka, connect 등을 docker compose 로 한번에 올리면서 타임아웃이 난 케이스였다. 30초에서 여유롭게 60초까지 늘려서 해결
bash -c 'echo Waiting for Kafka to be ready... &&
cub kafka-ready -b broker:29092 1 60 &&
kafka-topics --create --if-not-exists --bootstrap-server broker:29092 --partitions 1 --replication-factor 1 --topic products &&
echo Waiting 60 seconds for Connect to be ready... &&
sleep 60 &&
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://connect:8083/connectors/ -d "@/tmp/connectors/source_connector.json"'



